

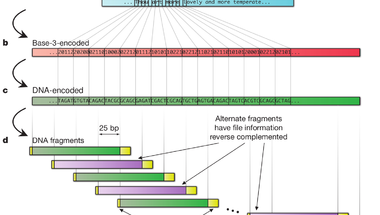
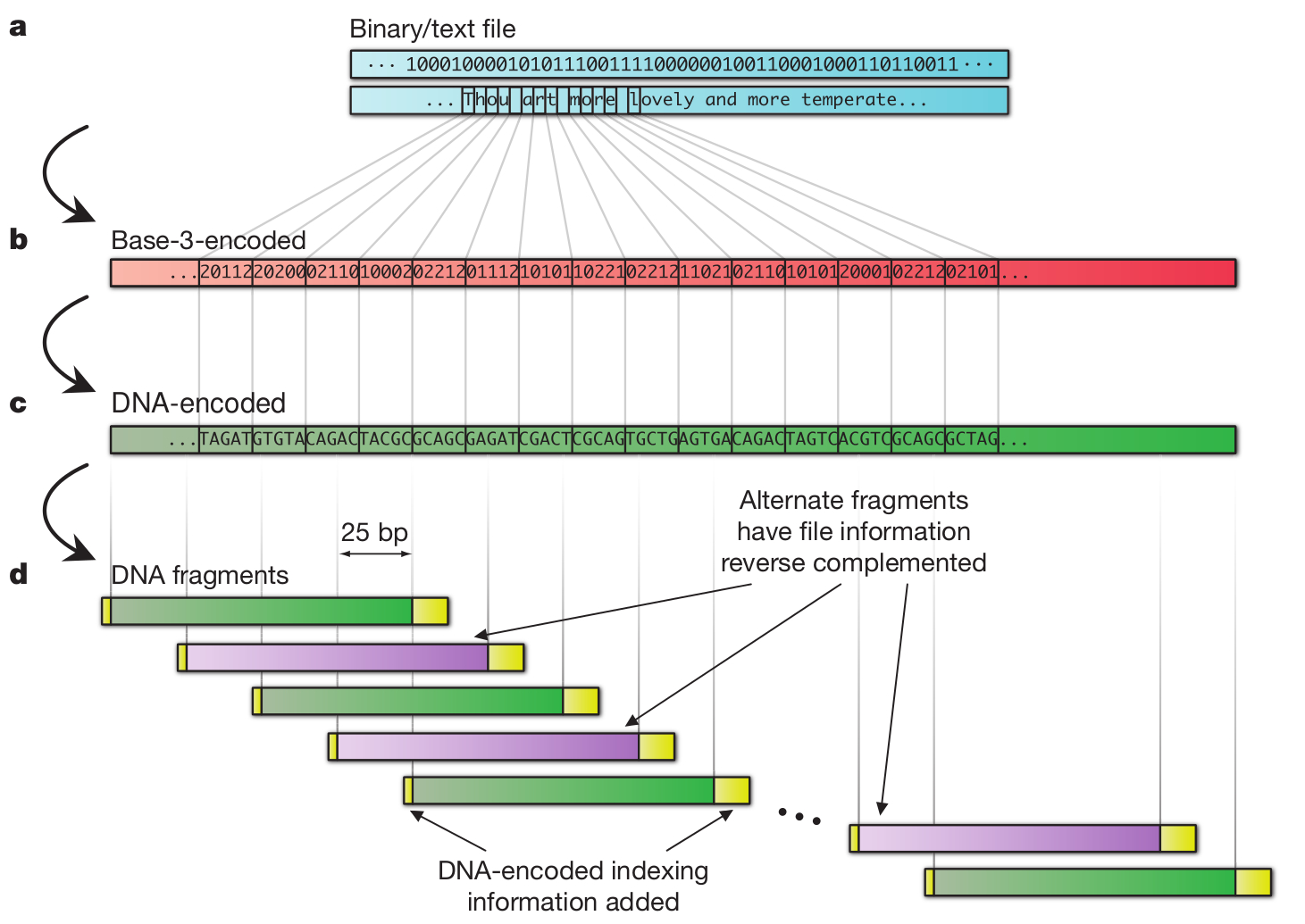
 Azt már szinte közhely, hogy egy DNS molekula alkalmas lenne hosszú távú adattárolásra, hiszen kis helyet foglal és bizonyítottan eláll évezredekig, miközben nem igényel különleges körülményeket. Viszont hátrányai is vannak, például a hosszú, adott szekvenciájú DNS szakaszok szintézise nem megoldott, azaz sehol sem tudnak neked tetszőleges bázissorrendű, egy gigabázis méretű DNS szálat készíteni. Ráadásul a bázissorrend meghatározása nem egyszerű és nem is gyors, de hát ez nyilván nem túl fontos szempont, ha évezredeken át meg akarunk őrizni valamilyen adatot. Nick Goldman és munkatársai (van köztük egy magyar is, Sipos Botond) éppen ezért kicsit másképpen közelítették meg a dolgot: Ismert bázissorrendű rövid DNS szakaszok könnyen és viszonylag olcsón szintetizálhatóak, így eleve ezeket használták föl adattárolásra. A 757 kilobytenyi kiválasztott adatot egy egyszerű kódtábla alapján DNS szekvenciává fordították, amely így nem tartalmazott ismétlődő bázisokat, mivel ezeknél gyakrabban lépnek fel hibák a második generációs szekvenálási eljárások során, így több hibával lennének csak kinyerhetőek az adatok. A csak elméletben létező hosszú DNS molekulát többféleképpen bontották rövidebb, egymással átfedő szakaszokra, így négyszeres lefedettséggel szintetizáltatták meg a molekulát, ezzel próbálták csökkenteni az adatvesztés lehetőségét. A végén egészen pontosan 153.335 oligonukleotidot terveztek meg, amelyek mindegyike 117 bázispár hosszúságú volt. Érdemes megemlíteni a szerzők megjegyzését, miszerint a teljesen egységes méretű DNS darabok és a homopolimerek teljes hiánya nyilvánvalóvá teszik, hogy a végeredményképpen kapott DNS nem természetes eredetű, így feltételezhetően szándékos tervezés eredménye és információt hordoz.
Azt már szinte közhely, hogy egy DNS molekula alkalmas lenne hosszú távú adattárolásra, hiszen kis helyet foglal és bizonyítottan eláll évezredekig, miközben nem igényel különleges körülményeket. Viszont hátrányai is vannak, például a hosszú, adott szekvenciájú DNS szakaszok szintézise nem megoldott, azaz sehol sem tudnak neked tetszőleges bázissorrendű, egy gigabázis méretű DNS szálat készíteni. Ráadásul a bázissorrend meghatározása nem egyszerű és nem is gyors, de hát ez nyilván nem túl fontos szempont, ha évezredeken át meg akarunk őrizni valamilyen adatot. Nick Goldman és munkatársai (van köztük egy magyar is, Sipos Botond) éppen ezért kicsit másképpen közelítették meg a dolgot: Ismert bázissorrendű rövid DNS szakaszok könnyen és viszonylag olcsón szintetizálhatóak, így eleve ezeket használták föl adattárolásra. A 757 kilobytenyi kiválasztott adatot egy egyszerű kódtábla alapján DNS szekvenciává fordították, amely így nem tartalmazott ismétlődő bázisokat, mivel ezeknél gyakrabban lépnek fel hibák a második generációs szekvenálási eljárások során, így több hibával lennének csak kinyerhetőek az adatok. A csak elméletben létező hosszú DNS molekulát többféleképpen bontották rövidebb, egymással átfedő szakaszokra, így négyszeres lefedettséggel szintetizáltatták meg a molekulát, ezzel próbálták csökkenteni az adatvesztés lehetőségét. A végén egészen pontosan 153.335 oligonukleotidot terveztek meg, amelyek mindegyike 117 bázispár hosszúságú volt. Érdemes megemlíteni a szerzők megjegyzését, miszerint a teljesen egységes méretű DNS darabok és a homopolimerek teljes hiánya nyilvánvalóvá teszik, hogy a végeredményképpen kapott DNS nem természetes eredetű, így feltételezhetően szándékos tervezés eredménye és információt hordoz.
A kész DNS -t liofilizálták (fagyasztva szárították), majd egyszerű postán küldték el az USÁból Németországba, mellőzve minden különleges csomagolási vagy tartósítási eljárást.
A csomagban kapott DNS bázissorrendjét egy második generációs szekvenáló platformmal határozták meg, ezt számítógépen illesztették össze, a nélkül, hogy a fogadó laborban bármit is tudtak volna a kísérlet tervezéséről, vagy a DNS elkészítésének részleteiről. Az eredetileg tárolt öt állományból (Shakespeare összes szonettje .txt állományban, Watson és Crick 1953 -as közleménye a DNS szerkezetéről .pdf formátumban, egy fénykép .jpg formátumban, Martin Luther King egy beszédének részlete .mp3 formátumban és a Huffman kód, amivel az adatokat DNS bázisokká fordították) négyet hibátlanul visszanyertek, az ötödikből két huszonöt bázisnyi szakasz hiányzott csak.
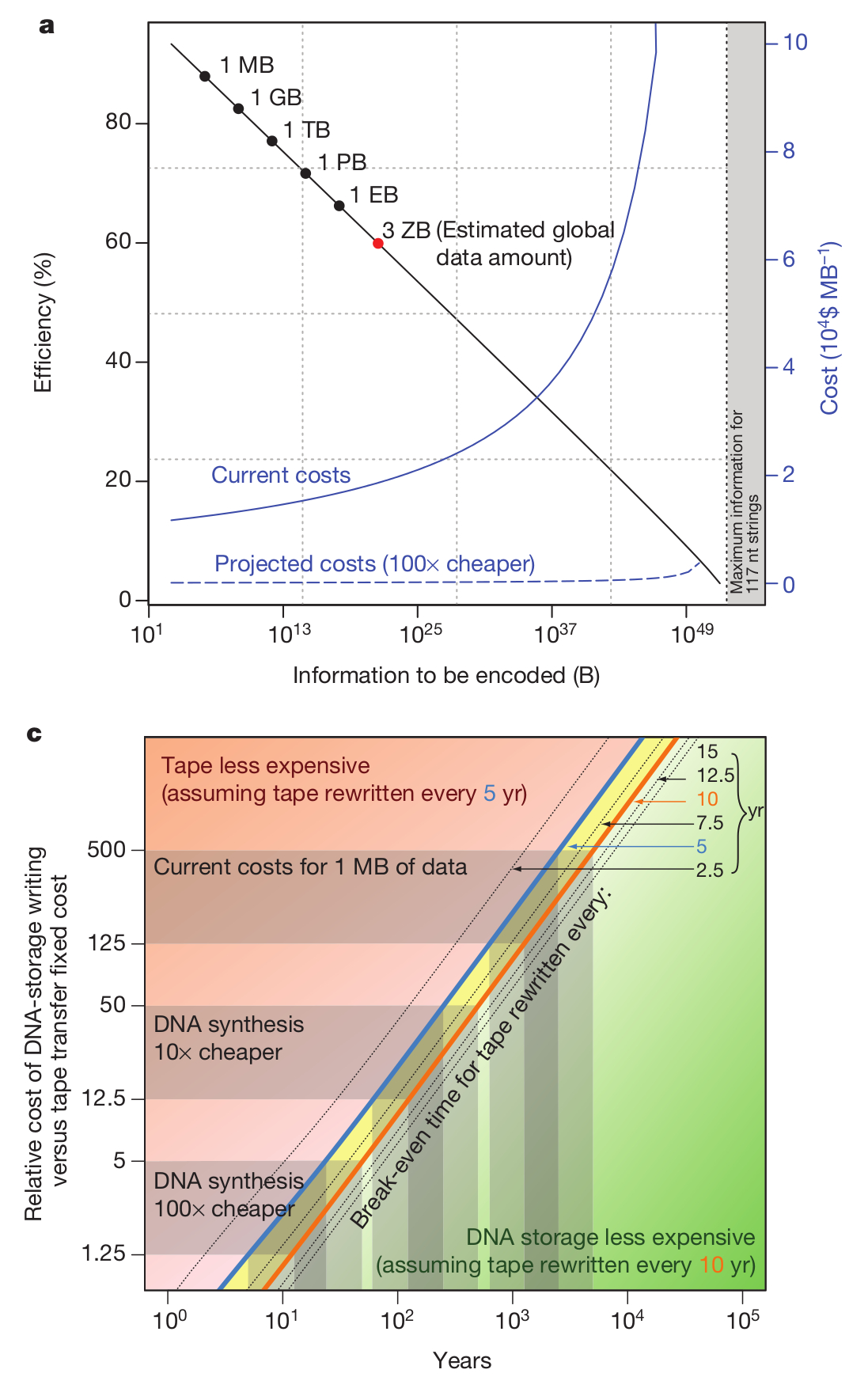 Még egy érdekes összehasonlítást tartalmaz a közlemény, ugyanis ebben a kísérletben egy megabyte méretű adattömeggel dolgoztak, de nyilván felmerül a kérdés, hogy ezzel a technológiával ennél nagyobb adatmennyiségeket mennyiért lehetne tárolni, hiszen a módszer költsége alapvető fontosságú szempont. Meglepő módon nagyobb adatmennyiségeket sem sokkal drágább így tárolni, a második ábrán ez látható, szédítő mennyiségű adattömeg kezelhető a jelenleg rendelkezésünkre álló módszerekkel, bár azért ez még mindig elég drága, legalábbis engem elriasztana a jelenlegi megabyteonkénti 12400 dollár az írásért, és 220 dollár/MB az adat elolvasásáért, bár nyilván ezt jelentősen csökkentené, ha a DNS szintetizálás és/vagy a szekvenálás olcsóbbá válna, vagy akár ha képesek lennénk hosszabb DNS szakaszokat szintetizálni. Viszont bizonyos felhasználási területeken, például kormányzati, vagy történelmi adattárolásra ez a módszer akár már most is olcsóbb lehet, mint a meglévők. Jelenleg a szerzők úgy becsülik, hogy ~600-5000 évnyi időtartamra számítva olcsóbb a módszerük a jelenleg használatos archiválási eljárásoknál, bár ez nyilván függ attól, milyen időközönként írják újra az adathordozókat. Viszont ebben az a sárkányosság, hogy ha az eddigi folyamatok folytatódnak, egy évtized múlva várhatóan százszor olcsóbb lesz a DNS szintézis és szekvenálás, viszont akkor már ötven évnyi időtávra is olcsóbb lesz DNS molekulákban adatot tárolni, mint mágneslemezeken. Szóval könnyen lehet, hogy pár ezer év múlva a régészek nem pergameneket vagy agyagtáblákat böngésznek majd, hanem szekvenálógépekkel dolgoznak.
Még egy érdekes összehasonlítást tartalmaz a közlemény, ugyanis ebben a kísérletben egy megabyte méretű adattömeggel dolgoztak, de nyilván felmerül a kérdés, hogy ezzel a technológiával ennél nagyobb adatmennyiségeket mennyiért lehetne tárolni, hiszen a módszer költsége alapvető fontosságú szempont. Meglepő módon nagyobb adatmennyiségeket sem sokkal drágább így tárolni, a második ábrán ez látható, szédítő mennyiségű adattömeg kezelhető a jelenleg rendelkezésünkre álló módszerekkel, bár azért ez még mindig elég drága, legalábbis engem elriasztana a jelenlegi megabyteonkénti 12400 dollár az írásért, és 220 dollár/MB az adat elolvasásáért, bár nyilván ezt jelentősen csökkentené, ha a DNS szintetizálás és/vagy a szekvenálás olcsóbbá válna, vagy akár ha képesek lennénk hosszabb DNS szakaszokat szintetizálni. Viszont bizonyos felhasználási területeken, például kormányzati, vagy történelmi adattárolásra ez a módszer akár már most is olcsóbb lehet, mint a meglévők. Jelenleg a szerzők úgy becsülik, hogy ~600-5000 évnyi időtartamra számítva olcsóbb a módszerük a jelenleg használatos archiválási eljárásoknál, bár ez nyilván függ attól, milyen időközönként írják újra az adathordozókat. Viszont ebben az a sárkányosság, hogy ha az eddigi folyamatok folytatódnak, egy évtized múlva várhatóan százszor olcsóbb lesz a DNS szintézis és szekvenálás, viszont akkor már ötven évnyi időtávra is olcsóbb lesz DNS molekulákban adatot tárolni, mint mágneslemezeken. Szóval könnyen lehet, hogy pár ezer év múlva a régészek nem pergameneket vagy agyagtáblákat böngésznek majd, hanem szekvenálógépekkel dolgoznak.
Goldman N, Bertone P, Chen S, Dessimoz C, LeProust EM, Sipos B, Birney E. (2013) Towards practical, high-capacity, low-maintenance information storage in synthesized DNA. Nature. 494(7435):77-80

